COO Magazine Q1 2024

Erkin Adylov
CEO
Behavox

Benchmarking Behavox Voice Against Leading Transcription Services.
Implementing a voice monitoring program in financial institutions is complex. It involves integration with recording equipment to collect voice files, transcribe these files, and provide users with a user-friendly interface (UI) for listening to and reviewing audio files alongside their transcripts.
Voice monitoring has posed significant challenges for financial services firms in the past. Firstly, transcription software often has a high error rate, resulting in transcripts that are virtually incomprehensible. Secondly, identifying problematic individuals or activities within voice communications has required manual review, involving the painstaking process of listening to audio recordings.
However, thanks to remarkable advancements in AI and cloud technologies, Behavox can now offer customers an affordable and automated solution for voice monitoring with unprecedented quality.
In this article, we will outline how we measure the quality of voice transcription for our customers, a service included free of charge as part of our voice offering. We will also compare Behavox’s voice transcription capabilities with those of several leading transcription services. Highlighting the significant benefits Behavox Voice brings to customers.
Introduction to Benchmarking
To assess the quality of voice transcription, the initial step involves obtaining a high-quality test dataset that has been transcribed by humans. There are several publicly available datasets that can be readily employed for benchmarking Automatic Speech Recognition (ASR), the scientific term for transcription, particularly when it comes to telephony speech. Two common examples are Switchboard and Fisher, which can be licensed from the Linguistic Data Consortium (LDC). Many conference papers often reference performance metrics on these datasets.
However, there are certain drawbacks associated with using such datasets for benchmarking:
- They are public datasets therefore it is not possible to benchmark third-party ASR vendors with confidence on these datasets as they most likely would have been used during training. Ideally, training and testing datasets have to be completely independent.
- Most importantly, if one wishes to understand what the performance of an automatic speech recognition (ASR) solution will be in the field, that is in a customer environment, then it is necessary to sample data directly from the customer. No other test will be better at forecasting ASR performance than this.
These insights are very important as they enable us to:
- Spot any potential unforeseen issues.
- Keep track of improvements in ASR transcription as the model is improved.
- Compare against other third-party cloud ASR vendors.
Regulatory Benchmarking Approach
The process begins with the collection of customer voice calls and the end result is a metric indicating the performance of Behavox and third-party cloud ASR vendors. In between there are several steps required to ensure that the test datasets created using customer data are of high quality. Automating as much of the pipeline is key to ensuring that benchmarking can be done as quickly, consistently and with minimal human error.
The process begins by requesting voice calls from the customer. The objective is to obtain a set of voice calls that will be representative such that any benchmarking performed would give an accurate picture of expected ASR performance for the given customer. As such there are certain requirements to ensure this:
1. Request for Customer Data
- A minimum of 60 different phone calls to enhance diversity is typically requested.
- The total speech duration must be at least 1 hour and a half. Anything less is unlikely to be representative of the customer calls.
- Phone calls must be complete and at least 1 minute in duration. Calls that are too short make it harder for annotators to grasp context leading to larger annotation error rates.
- There must be a large speaker diversity to capture speaker, gender, and ethnic variability and ensure an unbiased test dataset.
- Ideally, no duplicate calls are included (such calls will be filtered out at later stages).
- Calls must be real and from a production environment. Calls cannot be synthetic or artificially created. They should be from front office employees and not from support or IT.
2. Structuring the Voice Data
Each customer tends to provide voice data in different formats. The first step is to normalize this data such that the following steps in the pipeline work with consistent and structured data. This involves renaming files and following standard conventions, storing the data in specific locations in our secure data lake with clear timestamping to indicate when the data was received, and converting all the files to WAV format for consistency. After this stage is complete all datasets from all customers follow the same standard structure.
3. First Auditory Assessment
Typically after the voice data has been collected and structured into a standard format a team of in-house Behavox linguists will go over the data and listen to a random sample of calls. This simply ensures that there are no obvious issues that would require us to quickly get back to the customer and ask for rectifications. Such issues might be a lack of diversity in the dataset, unreadable format, corrupt audio files, artificially created calls, or unrepresentative data.
4. Duplicate File Deletion
In customer environments, it is typical that duplicate voice calls are stored. One reason for this is that all calls from all participants are stored even though the conversation is identical. Thus at times, the customer provides duplicate or near duplicate voice calls. This is not ideal as it reduces the diversity of the test dataset. Thus, an automated process at the signal level was conceived to remove such duplicates. The net result is a cleaned dataset with ideally no duplicate voice calls.
5. Automated Selection
Customers may provide more data than is necessary to perform ASR benchmarking with sufficient statistical accuracy. Given that human annotation of this data is costly one needs to devise a means to select a subset from this data. Typically the minimum should be one hour and a half. An automated pipeline was set up to sample from the given data such that it targets a specific required amount of speech. In addition, an internal speech activity detector model is used to remove large gaps of silence and filter calls that do not contain sufficient speech.
A language identifier model is used to filter out voice calls that have a high volume of foreign speech not in the target language (most customers would be benchmarking English ASR, but employees might be speaking other languages). In addition, we can optionally indicate to the selection pipeline to maximize speaker diversity provided that such information is included in the metadata. The final result is a set of wav files with the required speech duration which are to be used for ASR benchmarking.
6. Human Annotation
After the voice calls have been selected what follows is the human annotation process. This is the most important, but laborious and time-consuming part of the regulatory benchmarking, because the test dataset must be human-transcribed with the highest accuracy possible. Annotators are given strict guidelines on how to annotate the voice calls for consistency. At the end of the process, each WAV file will have a corresponding annotation file transcribing each speech segment in the call.
7. Automated Validation of human transcription
As the human-prepared transcripts are delivered to Behavox various automated checks are run on them to ensure their validity, thus guaranteeing that the annotators followed the guidelines. If the test fails the issues are reported to the annotation team who then proceed to correct these issues.
8. Second Auditory Assessment
Once again the Behavox in-house linguists perform an auditory assessment of a random sample of the human-generated transcripts against their corresponding voice calls to check the quality. If the quality of human transcription is found to be subpar, the annotation team is asked to correct these issues.
9. Regulatory Benchmarking
With human transcription of voice files completed, the customer test dataset is ready for regulatory benchmarking. An automated script is launched to transcribe voice files using Behavox ASR and third-party cloud ASR vendors. The final result of this is a report indicating where the ASR engine was correct and where it made errors in the form of deleted, inserted or substituted words. This includes an overall metric termed the word error rate (WER) which is commonly used to measure ASR performance. In the ideal situation, the WER is 0%, which indicates perfect transcription quality, but in practice given the noisy and highly compressed nature of narrowband telephony conversational speech, typical values of WER for a good ASR system will range from 20% to 40%.
One can similarly compare the reference annotations with the generated transcription on a character level instead of on a word level. This is termed the character error rate (CER). The advantage of using the CER over the WER is that it mitigates any trivial errors that result from text normalization mismatch between the reference annotations and the generated transcription. Examples would be “ok” in reference annotations not matching “okay” in generated transcripts or abbreviations such as “ibm” not matching “i b m”. These are two examples of normalization differences that can lead to trivial errors. CER also mitigates the impact of short filler word deletion (for example “uh”, “ehm” or “mm”) which has little semantic information. Like the WER the CER for a perfect ASR system would be 0% and typical values on real-world customer data would be in the range of 15% to 35%.
WER vs CER
Here are some examples of how the WER is typically higher than the CER due to mostly normalization or trivial errors. We present two such examples here, HUM refers to the human transcription and ASR refers to what the ASR model transcribed. The letters in bold-uppercase indicate the error. An asterisk in the human transcription implies that the ASR model inserted a word/character. Each asterisk in the ASR transcript indicates a deleted word by the ASR model.
In Example 1, there are two trivial errors: “hog” was incorrectly transcribed to the plural form “hogs” and the ASR system outputs “C A D” instead of “CAD”. These are trivial errors that result in a total WER of 25.0% due to 4 mistakes out of a total of 16 reference words. On the other hand, the CER is only 1.6% as the only error on a character level is the letter “s” for plural.
In Example 2 there is a similar trivial error, “oh” was transcribed as “ohh”. This leads to higher WER when compared to CER. Ideally, the WER and CER in this case is zero percent. In such a case this can be handled with normalization rules that mapped “ohh” to “oh”. In general, it is difficult to correct for all normalization issues and one can see from this example how CER helps reduce the inflated errors due to trivial mismatches between reference annotations and ASR transcripts.
Example 1
WER=25.0% (4 / 16)
HUM: uh selling a total of thirty contracts of lean HOG buying thirteen CAD * * buying
ASR: uh selling a total of thirty contracts of lean HOGS buying thirteen C A D buying
CER=1.6% (1 / 64)
HUM: uh selling a total of thirty contracts of lean hog* buying thirteen cad buying
ASR: uh selling a total of thirty contracts of lean hogS buying thirteen cad buying
Example 2
WER=33.3% (1 / 3)
HUM: OH that’s strange
ASR: OHH that’s strange
CER=6.7% (1 / 15)
HUM: o* that’s strange
ASR: oHh that’s strange
It is important to note that Behavox AI Risk Policies leverage state-of-the-art Large Language Models (LLMs), to overcome high WER and CER. The reason for this is that Behavox LLM is able to evaluate the entire sentence structure and as a result is able to derive context and meaning from multiple words and combinations of words. Lexicon or keyword-driven detective controls are highly likely to fail when used on voice files as any level of WER or CER however high will generate a high false positive rate.
Customer Test Datasets & Benchmarking Results
The following is a sample list of customer datasets that have been collected from customers along with benchmarking done on them across different vendors. The datasets are all narrowband telephony speech in English sampled from front office calls usually covering financial matters which are typical voice calls that our customers engage in.
The metric used is the CER calculated for the given customer. Table 1 details the CER per customer per vendor whereas the chart in Figure 1 gives an overview of the average performance across vendors.
Observe that Behavox has made a major step forward with its updated ASR solution Behavox Voice 20, which is scheduled for release with NextGen Behavox platform update in Q1 2024. It is better than OpenAI’s small whisper model (we selected OpenAI’s small whisper model as it is larger but closest in terms of the number of model parameters to Behavox Voice 20) and comparable to leading ASR vendors in the market. Observe that the quoted CER will have some degree of inaccuracy due to mistakes made during the annotation process as well as imperfect text normalization as previously mentioned. Thus the more accurate CER would typically be lower than the quoted results.
Table 1 – CER across different customers for different ASR vendors (August 2023 )
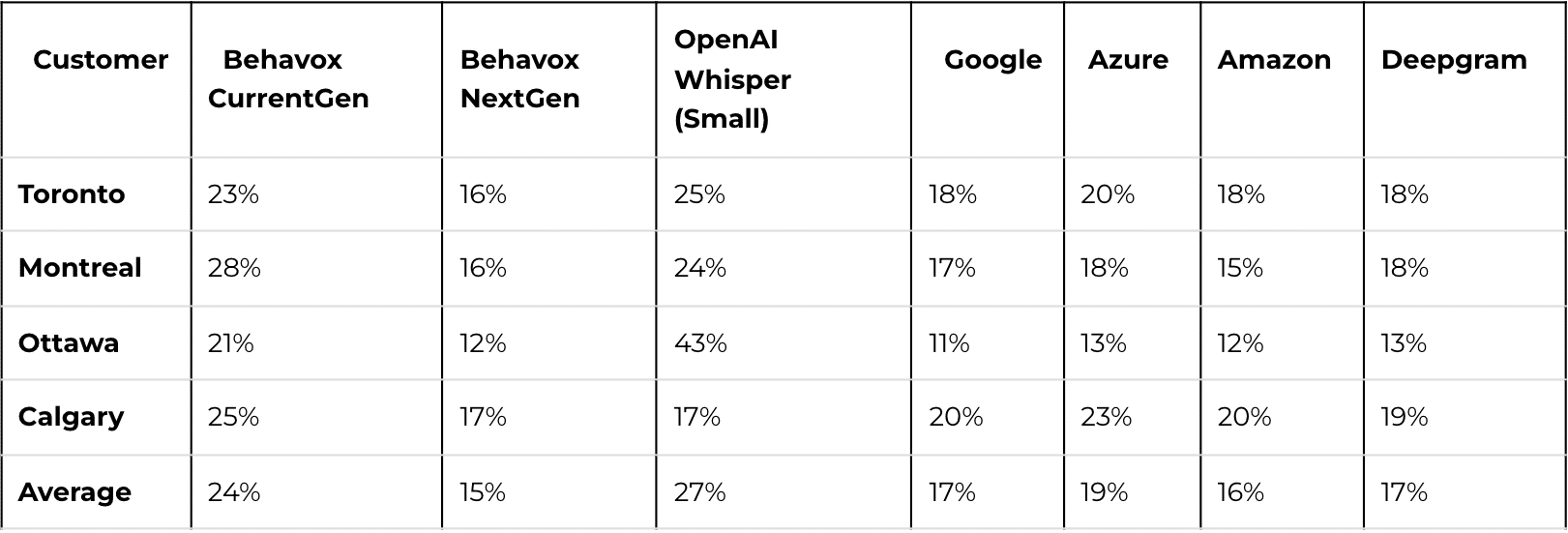
Figure 1 – Average CER across different ASR vendors
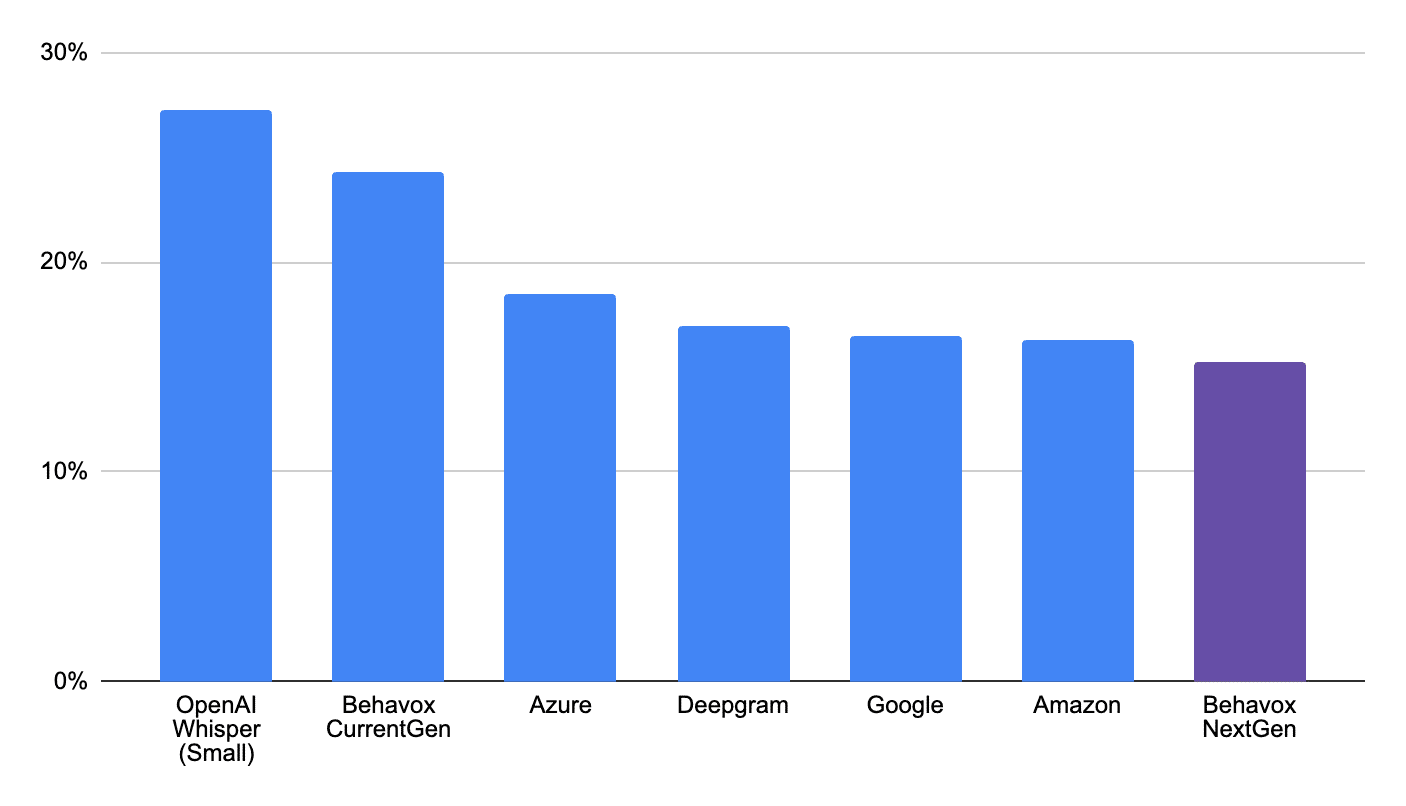
Table 2 – WER across different customers for different ASR vendors (August 2023)
